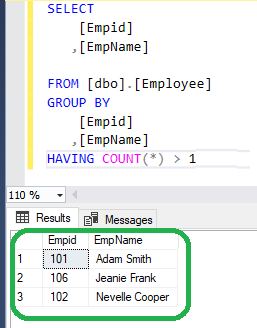
Finding duplicate values in SQL Server is a common requirement when cleaning data, identifying data quality issues, or enforcing uniqueness constraints. The simplest and most effective way to identify duplicates is by using the GROUP BY clause along with HAVING COUNT(*) > 1.
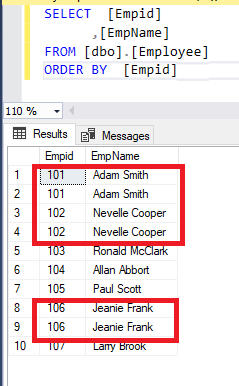
Sample Data – Below is the Employee table which has duplicate records
Below is the simplest T-SQL query to get the duplicate records
SELECT
[Empid]
,[EmpName]
FROM [dbo].[Employee]
GROUP BY
[Empid]
,[EmpName]
HAVING COUNT(*) > 1
Explanation of Query Execution
GROUP BY column_name- Groups the rows in the table based on the values in
column_namee.g. EmpID, EmpName. - Each unique value in the column forms a group.
- Groups the rows in the table based on the values in
COUNT(*)- Counts the number of records in each group.
- Helps identify how many times each value appears.
HAVING COUNT(*) > 1- Filters the grouped data.
- Only includes groups (i.e., values) that appear more than once, which means they are duplicates.
- Result
- The output shows only those values that are repeated in the specified column, along with the count of repetitions.