Python is a powerful and flexible tool for automating data movement between Excel files and databases like SQL Server. With libraries like pandas and sqlalchemy, you can build repeatable, error-free data pipelines—especially helpful for analysts and data engineers.
Environment Detail:
- Excel File Location: G:\Data\SalesData.xlsx (on local system)
- SQL Server Name: IND-SQL-01 (local installation)
- Database: BI_Reporting
- Target Table: dbo.SalesData
- Tool: Jupyter Notebook running locally (http://localhost:8888/)
Steps to Pull Data from Excel to SQL Server Using Python:
Step 1: Install Required Libraries:
!pip install pandas sqlalchemy pyodbc openpyxl
Step 2: Excel to SQL Workflow in Jupyter:
import pandas as pd
from sqlalchemy import create_engine
import urllib
# Load Excel
excel_path = r'G:\Data\SalesData.xlsx'
df = pd.read_excel(excel_path, engine='openpyxl')
# SQL Server connection setup
params = urllib.parse.quote_plus(
"DRIVER={ODBC Driver 17 for SQL Server};"
"SERVER=IND-SQL-01;"
"DATABASE=BI_Reporting;" # Replace with actual DB
"Trusted_Connection=yes;"
)
engine = create_engine("mssql+pyodbc:///?odbc_connect=%s" % params)
# Push to SQL
df.to_sql('SalesData', con=engine, index=False, if_exists='replace')
print("Data uploaded to SQL Server successfully.")
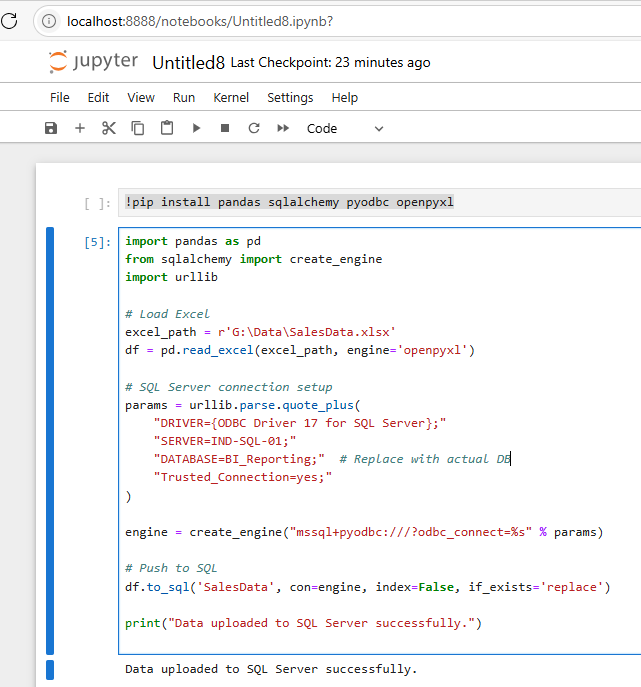
Step 3: Execute the Code and see the data into SQL Server Table:
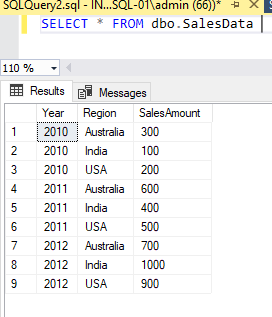
Result: We are able to load the data into SQL Server Table from Excel using Python & Jupyter Notebook